
Зачистка аудио ( Стенограмма защиты и транскрибация аудио в текст - Продолжение )

Для тех аспирантов, кто не был на прошлом уроке, скажу, что в понедельник, 9 июля, мы проходили стенограмму защиты диссертации.
Более 20 лет “Чёрный квадрат”
Малевича экспонировался
в Третьяковской галерее
вверх ногами.
(ссылка)
На мой взгляд, сохраняющаяся до сих пор документальная фиксация хода защиты квалификационной работы, в том числе на бумаге(!) – это совершенно необъяснимое явление, возникшее много-много лет назад в нашей стране по инициативе каких-то полудурков, командующих наукой. История не сохранила нам фамилии этих “новаторов”, но одно я могу сказать совершенно точно: либо эти люди пришли в руководство наукой из следственных органов или пенитенциа́рной системы, либо они явно страдали маниакально-депрессивным психозом.
Кстати, для жителей России покажется довольно странной, если не сказать больше, традиция жителей индийского штата Тамил-Наду. На проходящем там фестивале Аади священники должны разбивать кокосы о головы своих последователей. Причём аргументация такого членовредительского действа очень мощная: тем самым, местные жители выражают божествам благодарность, призывают удачу и здоровье(!). Но точно также индийцы, наверное, охренеют, узнав, что защитивший диссертацию в России должен предоставить следствию, пардон, ВАКу стенограмму своего допроса, извините, своей защиты.
Хотя и те и другие друг друга сто́ят. Индийцы уже давно не задают вопрос, почему удар по башке должен способствовать приросту здоровья, а россияне не спрашивают, нахрена нужен такой тотальный контроль защиты диссертации. В общем, “Хинди-руси бхай-бхай!”1) “Хинди-руси бхай-бхай” – “Индийцы и русские – братья!”..
Я думаю, что если задать ВАКу в лоб вопрос: “Когда вы отмените свою тюремную практику слежки за аспирантами и соискателями?”, то в ответ будет гробовое молчание. Или последует классическая реплика советской хамоватой продавщицы: “Не нравится – не бери!”.
Но как следует из практики лечебниц для душевнобольных, с психами или больными шизофренией лучше не спорить. Конечно, хорошо бы организовать в российских министерствах и в самом Правительстве ФАПы2)ФАП – фельдшерско-акушерский пункт., где бы чиновникам, министрам и членам Правительства по утрам кололи галоперидол. Чтобы они, хотя бы изредка, походили на нормальных. Иначе у меня складывается такое ощущение, что многие документы государственного значения эта руководящая свора подписывает, не приходя в сознание.
Сегодня я продолжу тему полуавтоматизированного формирования стенограммы защиты диссертации, начатую в материале “Игра слов”.
Кроме общих рассуждений о том, как хорошо быть здоровым и богатым, там был дан совет использовать видеохостинговый сайт YouTube для превращения записи процедуры защиты в текст. Этот ресурс позволяет сэкономить новоиспечённому кандидату наук частично время, усилия и нервы при подготовке стенограммы защиты своего диссера.
Но как уже упоминалось, результат очень сильно зависит от качества аудио записи. Попытки “скормить” YouTube звуковую дорожку, на которой даже вы – присутствовавший на защите, не можете ничего понять или разобрать, – не имеют смысла.
Сейчас я предложу вам два примера того, как YouTube расшифровал текст 5-минутного фрагмента лекции моей коллеги для аспирантов-первокурсников. В качестве первой реализации была взята исходная запись на смартфон. Вторая реализация – это уже результат обработки исходного звукового файла в “Adobe Audition 3.0”.
por que Испанский (создано автоматически)
1
los trenes que se ve
ah
esperamos vieron un punto
[Musica]
aqui y estamos duplicando
tambien esta puesto
[Musica]
y
van a descontar
compas
[Musica]
y
[Musica]
yo forme
Результат расшифровки необработанного звука для меня оказался чрезвычайно неожиданным. YouTube “понял”, что в записи говорят на испанском (испанском, Карл!) языке, и соответственно выдал 16(!) строк из пятиминутной речи. Конечно, Любовь Валериевна, как лингвист, знает несколько языков, а испанский также относится к романской группе, но лично я ни разу не слышал, чтобы она говорила на нём. Вот, спеть и сыграть на гитаре, она, конечно же, смогла бы. Но и гитары у неё в тот раз не было с собой.
А вот теперь глянем на результат работы YouTube с тем же 5-минутным фрагментом аудио записи, но обработанным в “Adobe Audition 3.0”.
[музыка]
я сегодня вам расскажу о международных
базам данных scopus
[музыка]
[музыка]
начнем с вами с нами пола scopus
мы ставим немного поговорим о на
versailles так вы все-таки раунд 1 года
до я думаю что у вас всех есть уже
публикации ли вы знаете что это такое не
у всех хорошо кто когда-нибудь слышал о
реферативных базу что это зачем мужчине
работали отлично есть ли у вас там
личный профиль колоть отлично есть слива
там ваша публикация с авторским
достаточно замечательно на самом деле
что такое стойкость скупость это наука
метрическая барабана
реферативные позитано которая была
создана голландскими строительство
когда скажем так науки стало появляться
огромное количество разных журналов
разных конференций появился
появилась потребность скажет качественно
отсеивать не самое хорошее новое и соло
вот из корпуса выдал санитар стан
реферативный вас данных они этим
занимаются они выбирают самые лучшие
журналы по разным специальностям всего
например 122
тематических специальности и по ним
проходит от всех сигналов попадание воды
по судам то есть если туда входит
конференция и в эту базу входит чем нам
это говорит или достаточно высоком
качестве то что мне стыдно таврика ваца
скажем так вашу публикацию будут читать
база данных scopus гораздо шире чем баз
данных волосами
сколько скучать себя около 20000 очень
большим количество но как я говорила не
развиты всего
направлением по тематикам более того все
журнал имеет свой собственный рейтинг
внутри самого заскок но нам этого чуть
похоже на голове
попасть журналу в эту базу данных не
очень просто подготовительный период
практически занимают не меньше чем два
года
обычно это 5-6 лет и знал подают заявку
или цельными по многим критериям в том
числе качество статей
естественно публикации по меньшей мере
аннотация
это нужно должна быть на английском
языке хотя сюда входят и русскоязычные
журналы и корейские журналы и испанский
на самых разных языках не только на
английском языке
требование одно все аннотации нужны не
столько на английском
мы тоже об этом немного похоже говорим
почему английский насколько у важный
благодаря открытию этих реферативных баз
данных появилась возможность оценивать
не только журналом только конференции но
и самих ученых насколько исследования
востребован насколько этим черные
знаменитых насколько они сделали прорыв
в своей области в целом можно даже
провести анализ по определенной
тематической области посмотреть кто в
мире чем занимается как каком
направлении она работает
насколько перспективно это направление
можно ли заниматься и дальше или
все-таки стоит уже поискать какие-то
другие пути
это все сегодня будем делать давайте
посмотрим это собственного титульная
страница который вы открываете заходите
на советскую кустов фокус доступен
только по подписке то есть это платная
подписка которой оформлять университетом
она стоит достаточно много денег
индивидуально нее форме дома не сможете
но тем не менее даже если у вас нет
доступа дома вы можете зайти на
стартовую страницу здесь вы не увидите
так много пунктов но здесь
Как видите, на этот раз никаких идальго и мучача бонита. Всё по-русски. Все девяносто(!) с лишним строк. Даже [музыка]! Почему уж YouTube не совсем разборчивый текст превращает в “музыку”, я не знаю. Ну, да ладно!
Теперь, господа бывшие аспиранты, вы понимаете важность предварительной обработки звуковой дорожки? Конечно, было бы круто отправить в ВАК стенограмму, в которой сплошняком бы шла [музыка]. Но эти сумрачные гении в Москве могут неправильно понять присуждение вам учёной степени кандидата технических или физико-математических наук за “музыкальное шоу”.
Я уверен, что некоторым продвинутым аспирантам мои советы по обработке звука в “Adobe Audition 3.0” покажутся, скажем деликатно, простоватыми. Но, во-первых, не у всех имеется опыт такой обработки. Во-вторых, отсылки к программным “монстрам”, наподобие “Adobe Audition CC 2018”, “Sound Forge Pro 12”, или пакетам мощных плагинов “Wave Arts Complete Bundle”, равносильны усаживанию не умеющего водить автомобиль новичка в какую-нибудь “Бугатти”, прости меня Господи. И в третьих, “вам шашечки или ехать?”.
Итак, господа пока ещё не защитившиеся аспиранты, я предлагаю вам посмотреть 22-минутный видео-урок о том, как “подрихтовать” аудио запись вашей будущей защиты. Я уверен, что это должно помочь вам минимизировать время и усилия при подготовке её стенограммы.
Подготовка аудио-записи для Youtube (1)
1. Видео с размерами 1280х720 можно посмотреть (скачать) на Youtube.
2. Те, кто хотят, могут сразу скачать видео размерами 960х540 (39 Мб)
Для тех, кто любит читать, а не смотреть “кино”, предлагаю текстовую расшифровку приведённого выше видео. С картинками. Расшифровка текста сделана с помощью того самого YouTube. Замечу, что в данном случае качество сформированного ресурсом текста оказалось достаточно высоким. Дурацких слов или словосочетаний было не очень много. На приведение текста, который YouTube “выдернул” из 22-минутного видео, в “нормальный” у меня ушло часа полтора.
Данный текст несколько отличается от того, что звучит в видео-файле. Он несколько “причёсан” и окультурен. Кроме того, по возможности убраны такие мои слова-паразиты, как “вот”, “значит”, “как-бы” и тому подобный словесный “мусор”.
Итак, читаем “многабукафф” и смотрим картинки.
Подготовка аудио-записи для Youtube (2)
Здравствуйте, господа аспиранты и сочувствующие!
Сегодня я расскажу о том, как подготовить аудио запись хода процедуры защиты вашей диссертации для того, чтобы YouTube смог её, более или менее удачно, трансформировать или преобразовать в текст.
Для этой задачи я пользуюсь портативной версией программы “Adobe Audition 3.0”. Это – очень хорошая программа. Взята мной, естественно, во временное пользование. Она достаточно легкая по сравнению с новыми монстрами 2015 или 2017 годов. Поэтому для вашей цели, для вот этой конкретно, можно и нужно, наверное, пользоваться ею.
Причем данную портабл версию – английскую, можно легко найти на просторах российского интернета. Почему английская? Потому что кривоватая русификация программы в некоторых пунктах меню у меня иногда вызывает просто раздражение.
Поэтому откроем файл, на котором я буду показывать как это делается.
В качестве примера я выбрал 5-минутный фрагмент записи лекции моей коллеги, которую она прочитала в прошлом году для аспирантов первого курса. Пять минут – чтобы было все понятно.
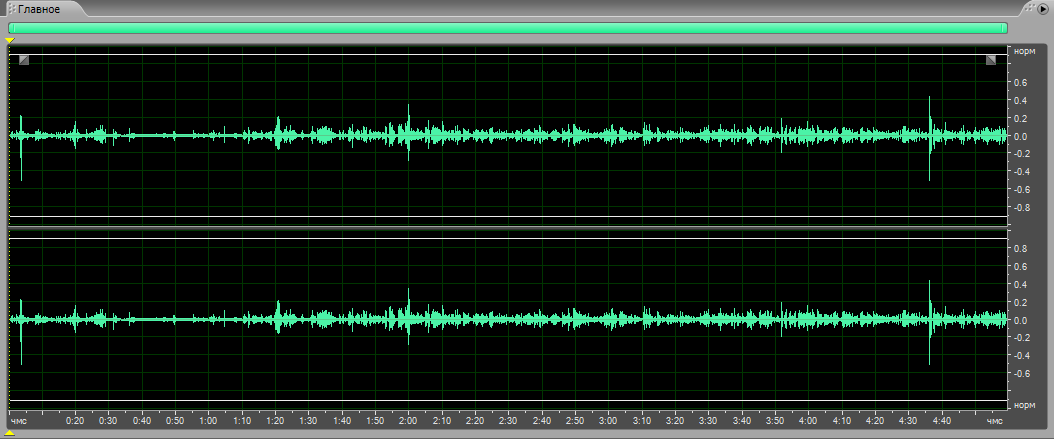
Данный формат файла m4a – это формат записи аудио. Сама запись была сделана на смартфон. Понятно, что это никакая не профессиональная запись: через хороший микрофон и на хорошей аппаратуре. Но зачастую встречаются ситуации, когда надо расшифровывать или обрабатывать именно такие записи. Поэтому берём то, что нам выдал смартфон.
Открываем файл.
Вуаля! Перед нами пятиминутная звуковая реализация.
Первая операция, которую нужно проделать с этим аудио-файлом, это нормализация амплитуды.
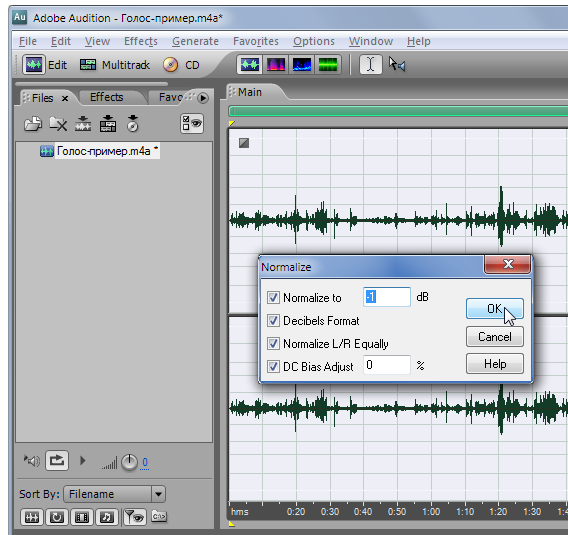
Открываем пункт меню «Эффекты» → «Амплитуда и Компрессия» → «Нормализация».
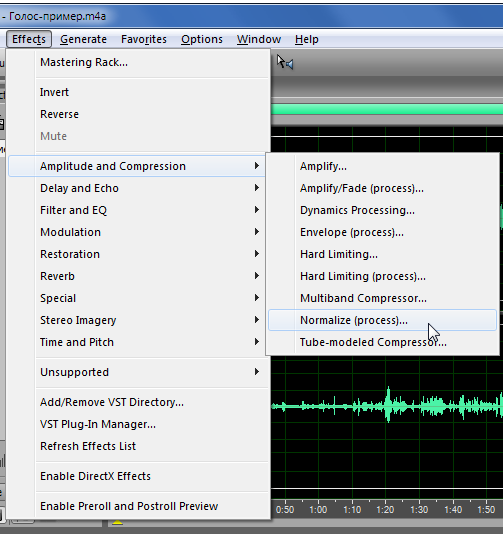
Нормируем мы амплитуду в правом и левом каналах к уровню -1 децибел, поскольку предварительно поставили галочку в пункте «Формат в децибелах» (“Decibels Format”). Ноль в пункте “DC Bias Adjust” стоит для того, чтобы удалить всю постоянную составляющую в этой звуковой реализации.
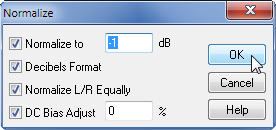
Нажимаем OK.
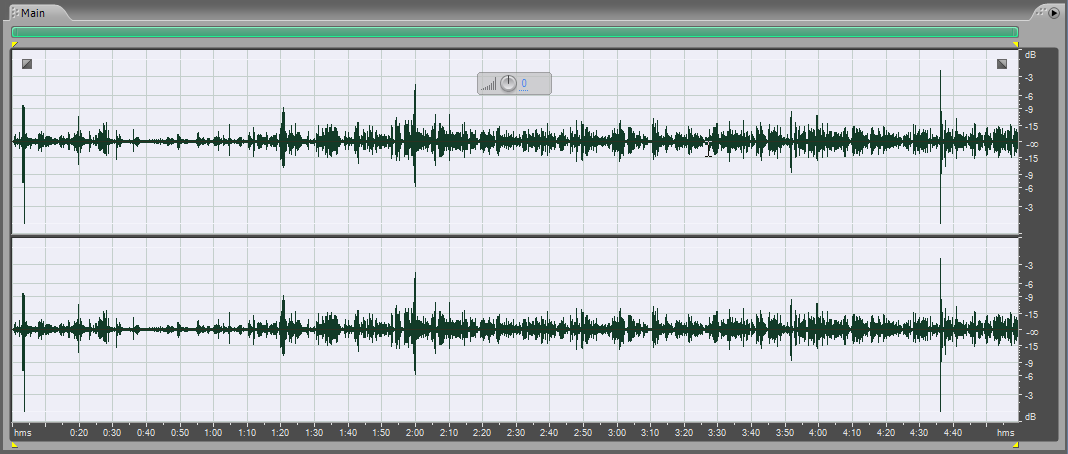
Как видим, сигнал подрос, но незначительно. И в этом ему “мешают” вот такие участки – некие амплитудные “выбросы”.
 |
 |
 |
Хочу сказать, что аудиозапись, особенно аудиозапись хода защиты диссертации, никогда не проходит в идеальных условиях. Во-первых, там, где собирается больше двух человек, всегда шум-гам. А когда в зале сидит 20 членов диссовета, да плюс приглашенные, вы можете представить, какой иногда там стоит хай. Причем члены диссовета, как правило, люди возрастные. Им вольно сморкаться, кашлять, ерзать стульями, разговаривать между собой. Я много раз был на защитах, когда председателю приходилось делать замечания некоторым членам диссовета за то, что они там практически в голос разговаривали между собой. Ну, высокий культур-мультур. Именно так всё и происходит.
Посмотрим, например, что вот это за фрагмент.
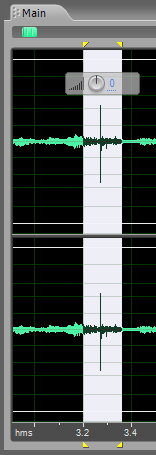
И послушаем. Понятно: то ли щелчок, то ли стук.
Следующий «выброс».
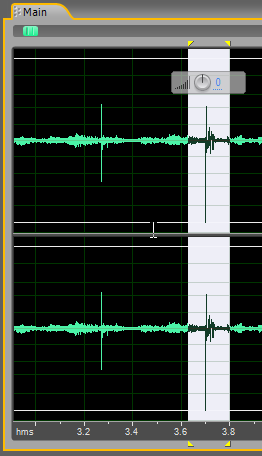
То же самое.
Как с этим бороться? Бороться именно с такими коротенькими «выбросами».
Сразу добавлю, что, если запись длинная по времени и вот этих «выбросов» или «шума» дополна и больше, то не тратьте время на “ручную” обработку. Конечно, качество обработанной записи пострадает без их удаления. То есть, если запись не будет «почищена», то это, безусловно, повлияет на качество распознавания текста YouTube. Но если таких «выбросов» много, то и времени вы потратите немало. Хотя если упорного и опытного товарища попросить… То он вам за бутылку коньяка сделает. Автоматическому удалению или чистке я бы не доверял. Как правило, при этом “вместе с водой выплёскивается и ребёнок”.
Итак, имеем вот такой выброс.
Как его ликвидировать?
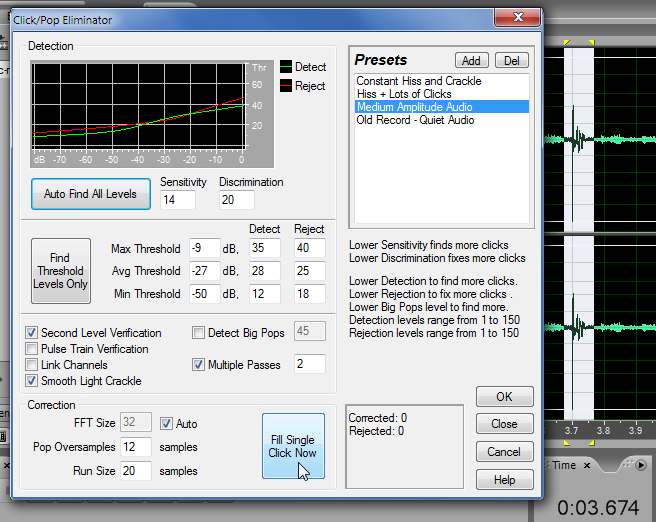
Достаточно просто. Выделяем этот «выброс» с небольшими «окрестностями» на временно́й шкале. Затем находим пункт меню для удаления всяких «выбросов» и прочей фигни: «Эффекты» → «Восстановление» → “Clic/Pop Eliminator (process)”, и тюкаем по этому пункту.
После этого откроется следующее окно.
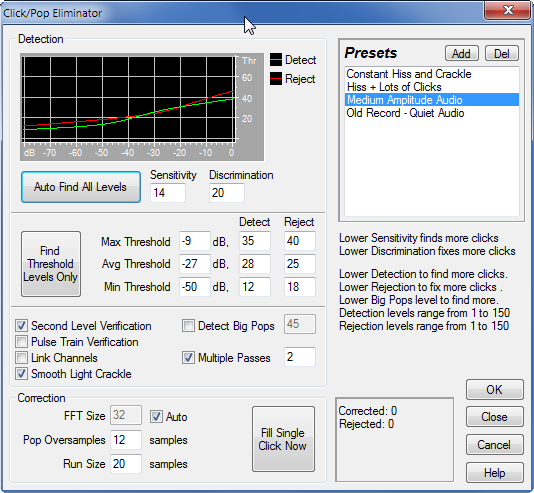
У меня уже по умолчанию был выбран пресет “Medium Amplitude Audio”, хотя иногда задействованы другие предустановки. Но я выбираю, как правило, именно этот – для аудио записи со средней амплитудой. Никаких настроек при этом не меняю. Хотя при желании можно «поиграться». В ряде случаев это даёт эффект. И для того, чтобы удалить этот короткий «выброс», мы просто нажимаем кнопку “Fill Single Click Now”. И всё.

Программа обработала этот фрагмент и удалила данный «выброс». Можно послушать. Никаких щелчков или стука практически не слышно.
То же самое проделаем со вторым “выбросом”.
Удалили!
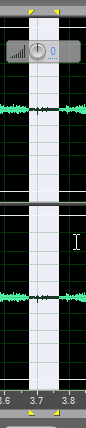
А вот это что за фрагмент?
Сейчас глянем поближе и послушаем. Понятно, что кто-то кашлянул. Ну, не кто-то, вообще-то, а я. И как-то ликвидировать этот «кашель», который наложился на речь преподавателя – Любовь Валериевны, практически невозможно. Да это и не стоит делать. Потому что вместе с «кашлем» мы уберём или сильно исказим, собственно говоря, и полезную голосовую информацию. Единственное, что можно проделать – это просто уменьшить амплитуду фрагмента. Это тоже делается очень просто. Выделяем фрагмент записи с «кашлем». Выбираем пункт меню «Эффекты» → «Амплитуда и Компрессия» → «Усиление».
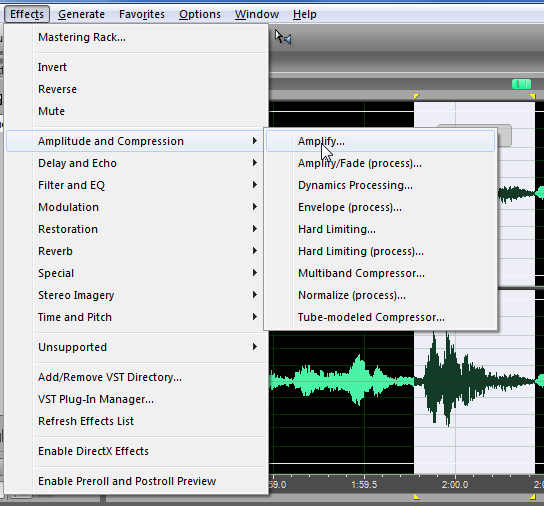
И тюкаем по нему. Откроется следующее окно.
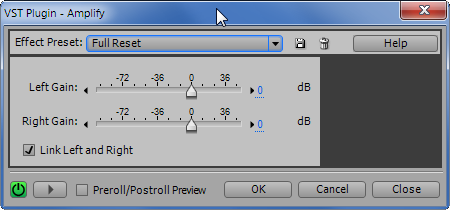
По умолчанию стоять может любой из пресетов (“Effect Preset”). Но поскольку нам нужно уменьшить амплитуду сигнала, выбираем “-6 децибел”. Если вдруг такой предустановки не оказалось, выставляем нужное усиление “ручками”.
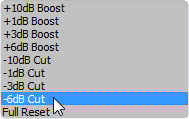
И жмём OK.
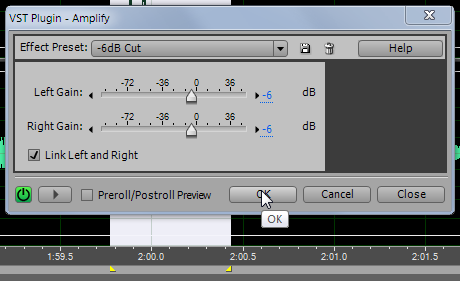
В результате, амплитуда данного «выброса» уменьшилась и практически сравнялась с «соседями».
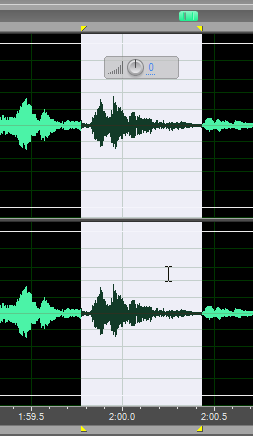
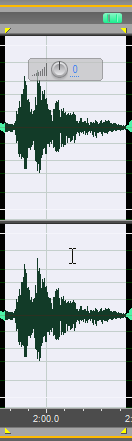
Так, а вот это что такое?
Сейчас “растянем” фрагмент по оси времени и послушаем.
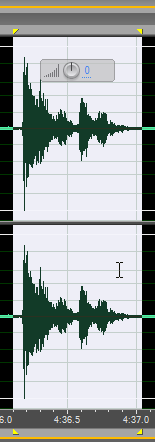
Ну, в общем понятно. Любовь Валериевна тогда была простывши, поэтому данный «выброс» – это её кашель в полный рост. И такое на защитах сплошь и рядом. Не только кашель, а ещё как бы сморкание вы там не услышали. Ну, ладно.
Бороться с этим вообще очень просто. Можно просто нажать кнопку “Del” на клавиатуре и удалить выделенный фрагмент к чёртовой матери. Либо выбрать пункт меню «Редактировать» → «Вырезать». И привет!
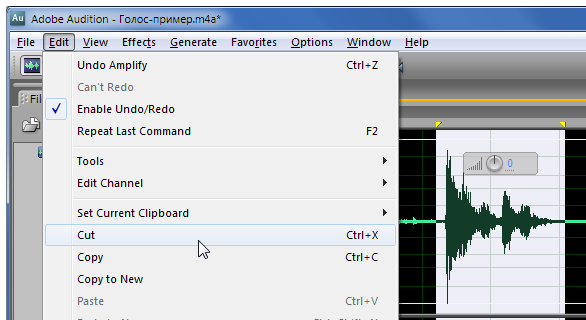
Кашля как не бывало! Если бы было так легко в жизни с кашлем. Это я про себя.
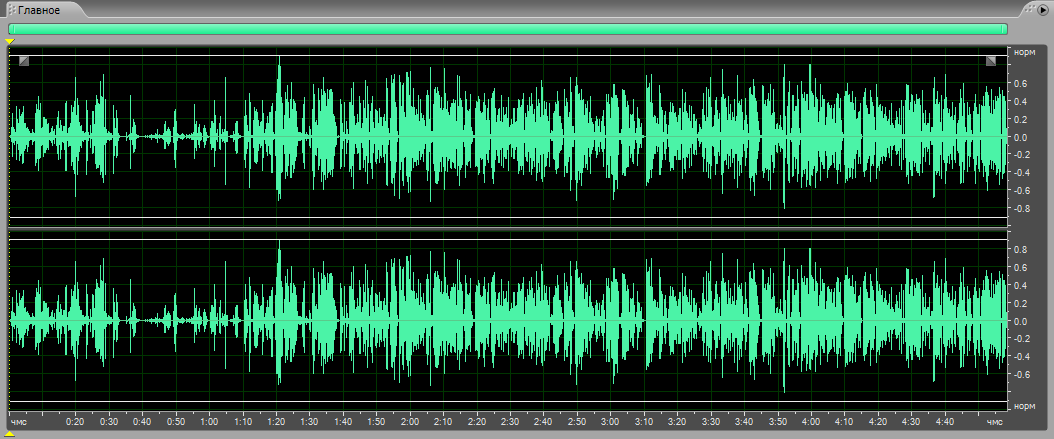
Таким образом, в данной реализации мы избавились от неких амплитудных «выбросов». Что позволяет нам ещё раз обратиться к пункту меню нормализация и «поднять» весь этот звуковой ряд повыше.
Жмём OK.
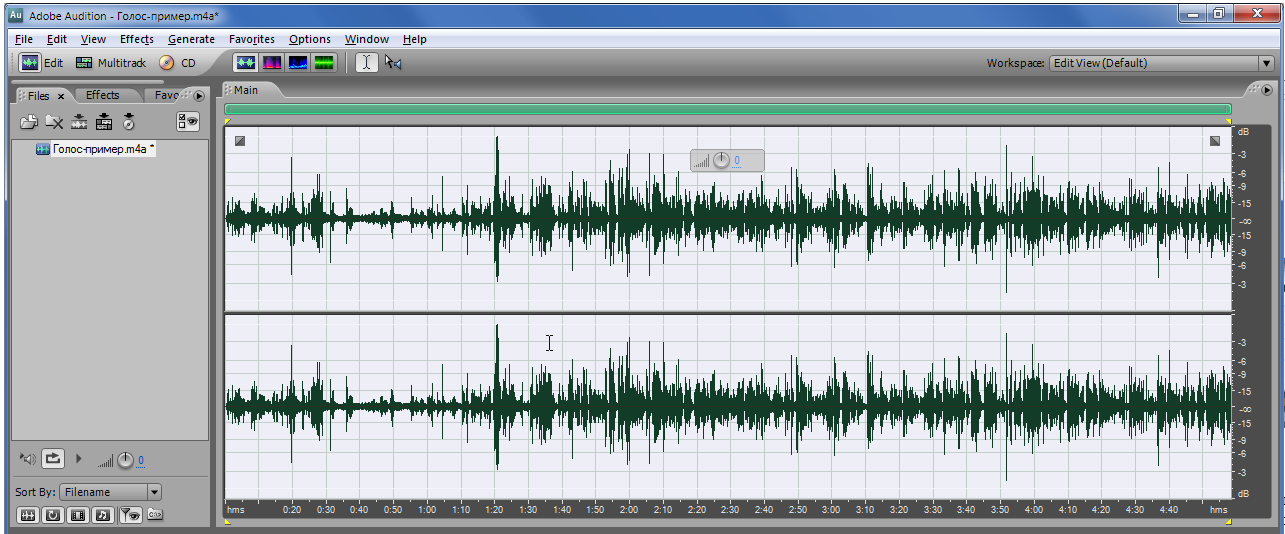
Итак, мы видим, что, в принципе, эту запись уже можно закидывать на YouTube и «скармливать» ему так, как я вас учил в прошлом материале: создавая видео файл из статичной картинки и «приклеивая» к нему звук.
Но, давайте попытаемся быть перфекционистами и попробуем ещё улучшить качество этого звукового файла. Каким образом можно этого добиться?
Одним из вариантов подавления ненужного фонового уровня является ликвидация гармоник сигнала с частотой 50 герц. Выделяем (“Ctrl-A”) всю реализацию. Выбираем пункт меню «Эффекты» → «Фильтр и Эквалайзер» → «Режекторный фильтр»
и тюкаем по “Notch Filter”.
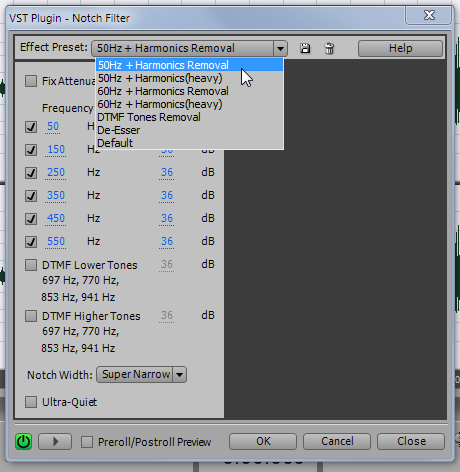
По умолчанию у меня выбран пресет «50 герц + удаление гармоник». Потому что 60 герц – это не про нас, а про американцев. Пресет «50 герц + гармоники (сильные)» не выбираем, поскольку в аудиозаписи фон 50 герц проявляется слабо.
Жмём OK.
Таким образом, подавляется частота 50 герц и её нечетные гармоники. После обработки мы увидим, как изменится внешний вид у этой звуковой реализации. Она должна немножко «подсесть». Сейчас мы в этом убедимся.
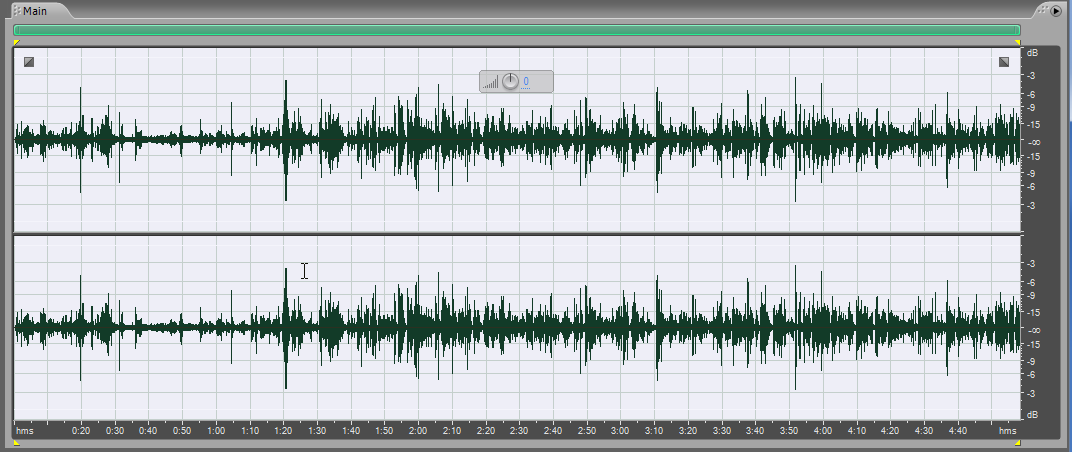
«Подсела», как и должно было быть.
Следующий этап – это подавление собственно шума реализации. «Шум» – не в смысле выкриков профессоров из зала по поводу вашей диссертации или возня за столом заседаний, а некий звуковой фон самого помещения.
В помещении, где проходит защита, наверняка будет включен свет, поскольку в темноте защищаться сложновато. Будет стоять проектор, который издаёт звук. Может быть, в зале имеются кондиционеры, роутеры и прочее оборудование, которое вносят свою гудяще-жужжащую лепту в общий звуковой фон. Поэтому очень полезно сделать хотя бы 5-секундную запись данного помещения «вчистую» – без гомонящих членов диссертационного совета и прочих присутствующих. Чтобы иметь образец этого фонового шума.
Хорошо, что на этой 5-минутной реализации есть участок незанятый речью. Любовь Валериевна в тот момент, наверное, что-то перелистывала или просматривала свои записи, или что то ещё. Поэтому такой участок можно найти примерно где-то вот в этом “районе”.
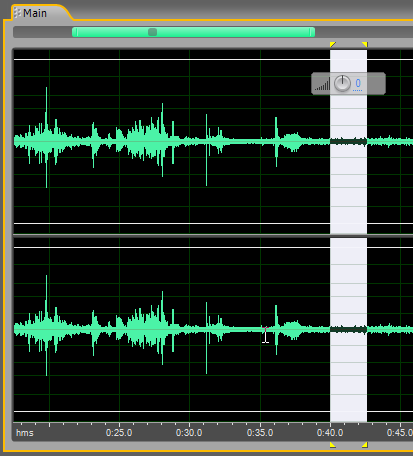
Подавить шум в аудио записи можно с использованием этого участка, выбранного в качестве «образца», а можно сначала провести предварительную частотную фильтрацию всей реализации.
Наша аудио запись – это речевой сигнал. Никаких электрогитар, синтезаторов или частот 16 кГц и выше, в ней нет по умолчанию. Визжать с такой частотой по поводу ваших ответов профессора уже не могут в силу возраста. Даже если бы и хотели. Поэтому, в принципе, нужно «пройтись» по всей этой реализации полосовым частотным фильтром.
Это можно сделать, например, вот так.
Для начала выделим всю реализацию. Выбираем пункт меню «Эффекты» → «Фильтр и Эквалайзер» → «Графический эквалайзер».
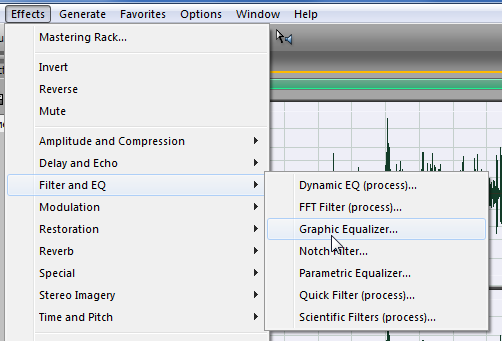
Тюкаем по пункту “Graphic Equalizer”.
Как видим, в программе “Adobe Audition” имеется большое число пресетов с разными частотными характеристиками. Опыт показывает, что для реализаций с записью голоса в помещении нужно придавить низкочастотную область до 100 Гц и подавить частоты свыше 5 или 6,3 кГц, плавненько сведя всё к нулю.
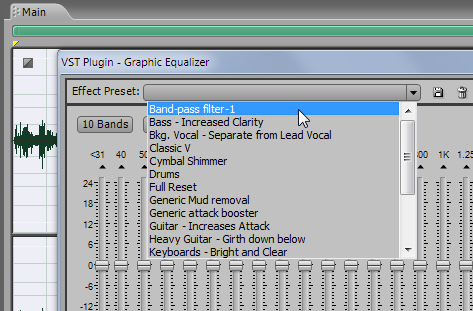
Для подобных аудио записей у меня уже прописан пресет “Band-pass filter-1” для случая 30-полосного эквалайзера. Выбираем этот пресет.
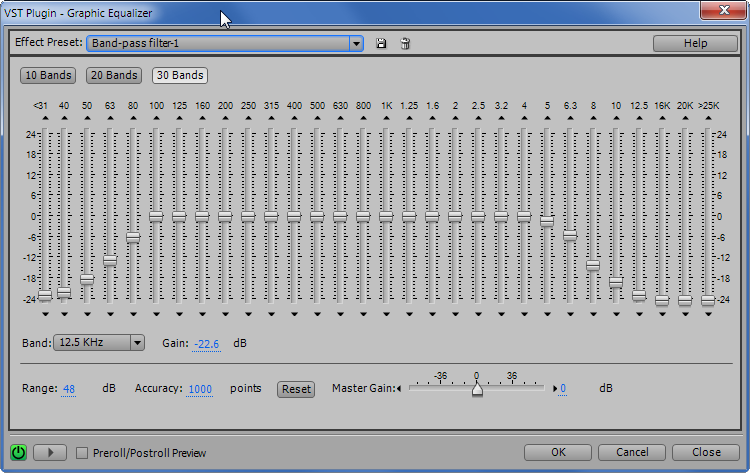
Нажимаем OK. Но результат частотной фильтрации, который вы увидите, не будет кардинальным. Вся реализация лишь чуть-чуть “подсядет”.
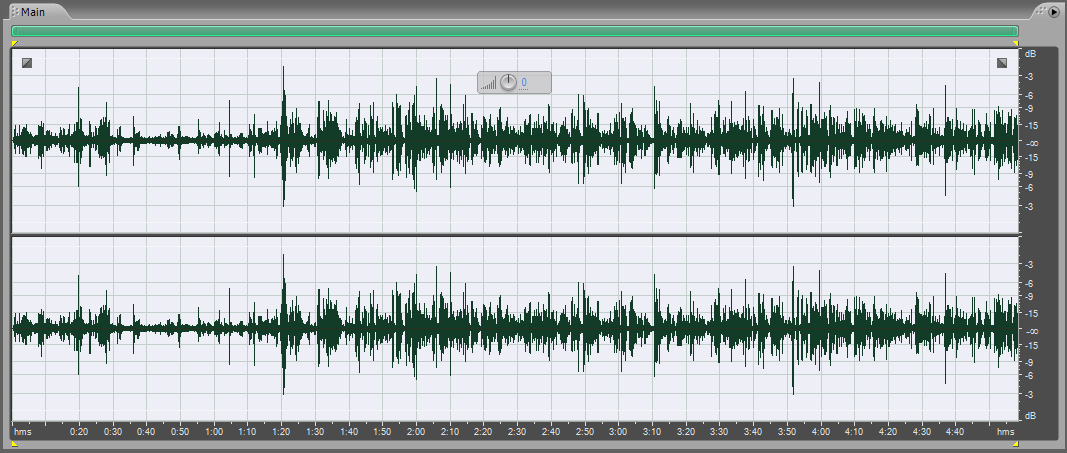
После данного фильтра в записи подавились низкие частоты, а по высоким частотам вы бы и не увидели, как и что там «задавилось». Но я вас уверяю, что вот эта операция является достаточно полезной.
Правда, иногда приходится вручную, путём подбором, регулировать характеристику «Графического эквалайзера» или «Параметрического эквалайзера» (“Parametric Equalizer”) в том же пункте меню «Эффекты» → «Фильтр и Эквалайзер», чтобы убрать посторонние призвуки или искажения голоса. Замечу, что в старших версиях “Adobe Audition” имеются более продвинутые инструменты фильтрации.
После того, как мы ограничили спектр сигнала, можно приступить к самому процессу шумоподавления. Выберем какой-нибудь кусочек записи, ну, например, вот такой.
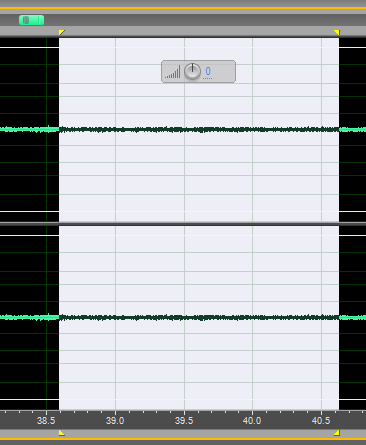
Причем убедитесь, чтобы во фрагменте, который вы идентифицировали как «чистый шум», не было каких-то выбросов или обрывков речи. Потому что, если вы выберете в качестве «образца» для шумоподавления фрагмент вместе с речью, допустим, оппонента или с вашим голосом, а потом «подавите», то вы «подавите» или исказите голос уважаемого профессора, а, может быть, и своё блистательное выступление.
Если прослушать этот кусочек, то в этом фрагменте не слышно звуков речи, а звучит достаточно однородный шум, который можно уже «давить». Как это сделать?
Выбираем пункт меню «Эффекты» → «Восстановление» → «Подавление шума»
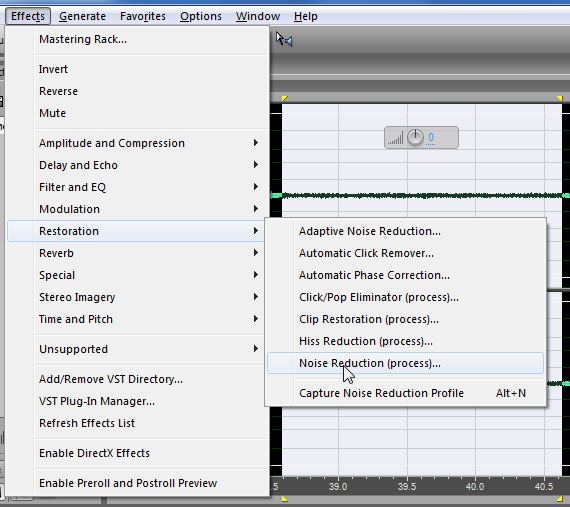
и тюкаем по нему.
Поскольку “Adobe Audition” не семи пядей во лбу, то ему надо, чтобы вы «скормили» ему образец собственно шума. Для этого существует кнопочка “Capture Profile”. Щёлкаем по этой кнопке.
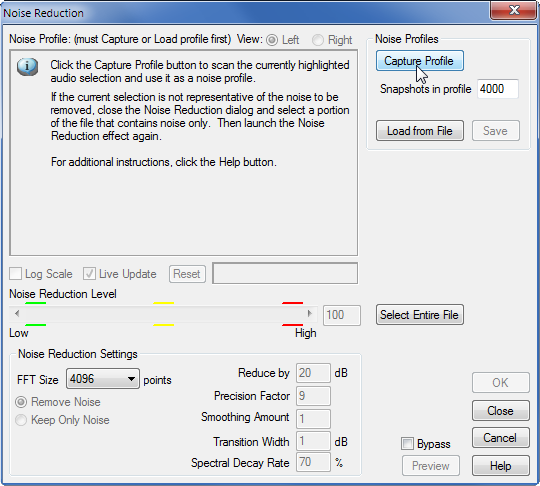
В результате мы получили спектр шума выделенного нами участка аудио записи.
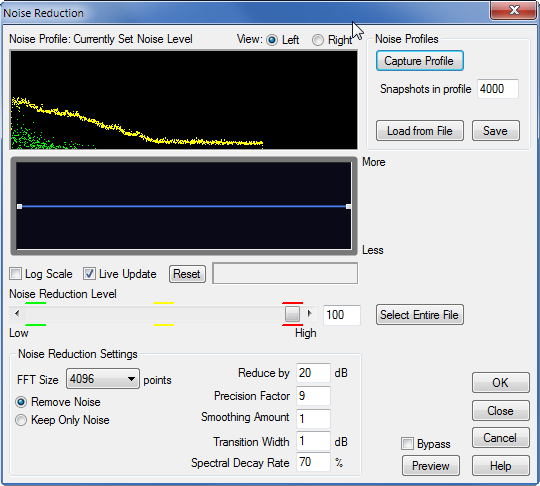
По умолчанию, параметр «Уменьшить на … дБ» (“Reduce by”) в исходных установках “Adobe Audition” выставлен в 40 децибел, то есть шум давится в сто раз. Когда я поначалу столкнулся с обработкой голосовых записей, у меня стояла именно эта величина. Но потом выяснилось, что значение 40 децибел излишне большое, поскольку в ряде случаев оно вызывает одновременно и искажения самого голоса. Причем достаточно заметные. Поэтому ставим компромиссную величину этого параметра обработки в 20 децибел.
По умолчанию, значение фактора или коэффициента точности было равно 7, переходная полоса (“Transition Width”) равнялась 0 дБ, а Spectral Decay Rate было задано в 65%. Я изменил эти величины на 9, 1 дБ и 70%, соответственно.
Количество точек преобразования Фурье оставляю то же самое – 4096. Нажимаем ОК. Как видим, шума практически не видно. Да и не слышно.
Для того, чтобы подавить шум во всей реализации мы
“откатываем” назад последнюю операцию.
Затем выделяем все реализацию и по той же «схеме» «Эффекты» → «Восстановление» → «Подавление шума» давим шум. Все предыдущие настройки, включая профиль шума, остались прежними. Поэтому жмем OK и ждем,
пока шум не будет подавлен во всей звуковой реализации. Если у вас длинная реализация – полтора часа или больше, то и времени на каждую операцию обработки у вас уйдёт поболее. Многое зависит от компьютера, на котором вы это все будете делать. На хорошей машине это делается достаточно быстро.
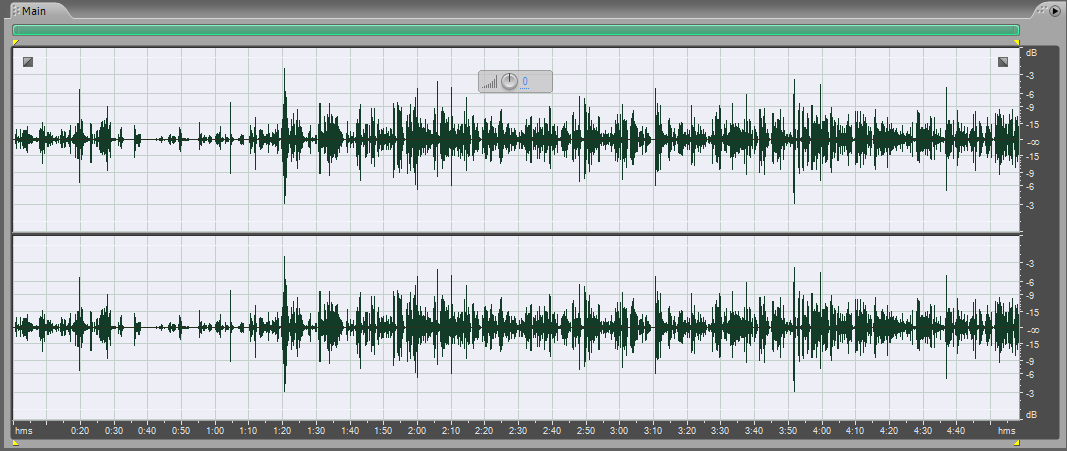
Всё! Шум подавлен.
Однако запись всё равно достаточно неравномерная по амплитуде. Потому что в какой-то момент Любовь Валериевна отворачивалась и говорила в сторону.

В другой – она, наоборот, повернулась прямо к телефону, который лежал на столе.
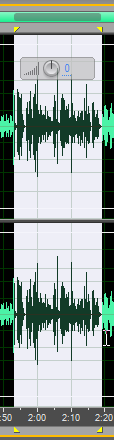
Поэтому здесь уровень записи «поплотнее» и повыше.
То есть сигнал-то надо компрессировать или “поджать”. Потому что во время защиты уровень звука тоже будет записан абсолютно неравномерно. Уважаемые члены диссовета, оппоненты и другие товарищи во время своих выступлений, реплик и устного разноса вашей диссертации, как правило, вертят головой во все стороны от микрофона, да и вы сами не всегда будете в микрофон попадать. Поэтому сигнал нужно сжать по амплитуде, чтобы добиться некоего общего среднего уровня.
Каким образом это можно сделать?
Это можно сделать, войдя в меню «Эффекты» → «Амплитуда и Компрессия». И вот тут есть такой подпункт, как “Dynamics Processing”, то есть обработка сигнала в динамике или динамическая обработка, как хотите.
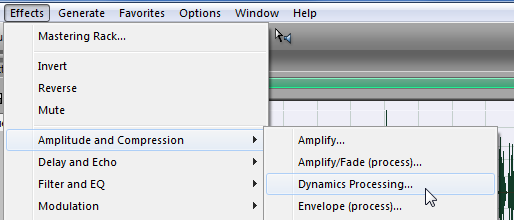
Нажали. И, в открывшемся окне у меня по умолчанию стоит уже вот такая вот “кривулина”.
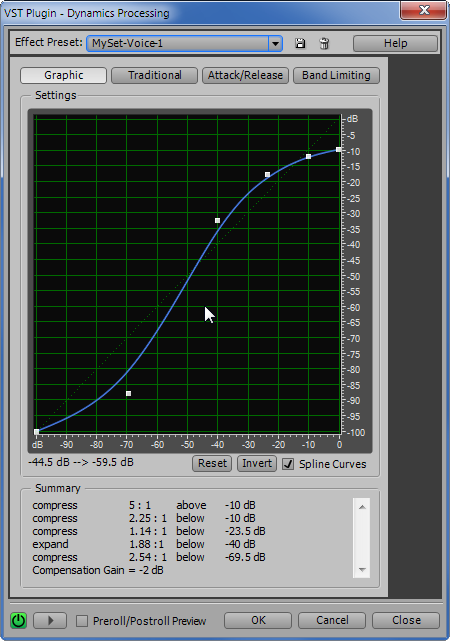
То есть все амплитуды, меньшие примерно -47 дБ и большие -14 дБ, будут “поддавливаться”, а амплитуды внутри этого диапазона – будут усиливаться.
Данная характеристика была создана на базе пресета “Boomy Kick”, предназначенного для обработки звучания барабанов. Вот так графически выглядит эта “барабанная” характеристика.
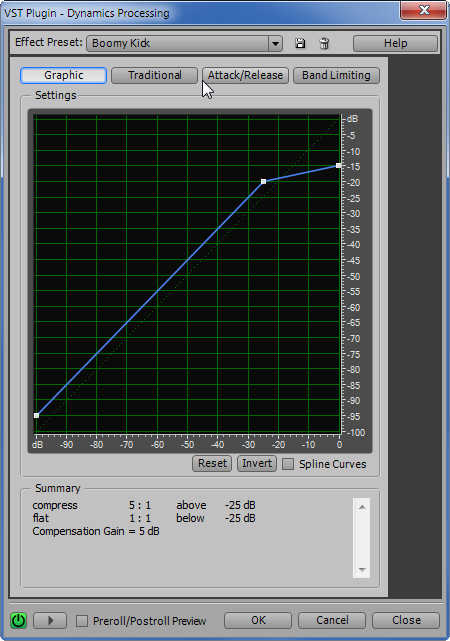
Чтобы получить вид характеристики как на предыдущем рисунке, захватываем крайнюю левую точку и тащим её в -100 дБ. Среднюю точку сводим чуть ниже пунктирной диагонали. Для чего это делается? Это позволяет слегка снизить реверберацию помещения и в какой-то мере поддавить эффект «голоса из бочки». Конечно, совсем убрать реверберацию вам не удастся. Но вот этот небольшой «финт» позволяет её несколько уменьшить.
А чтобы амплитуда сжималась «поровней» или «плавнее», то можно поиграться, добавляя свои точки, как вам угодно. Эти точки можно таскать вверх или вниз, изменяя характер кривой Всё зависит от самой звуковой реализации и вашего опыта.
Итак, создали характеристику, похожую на пресет “MySet-Voice-1”. Жмем OK.
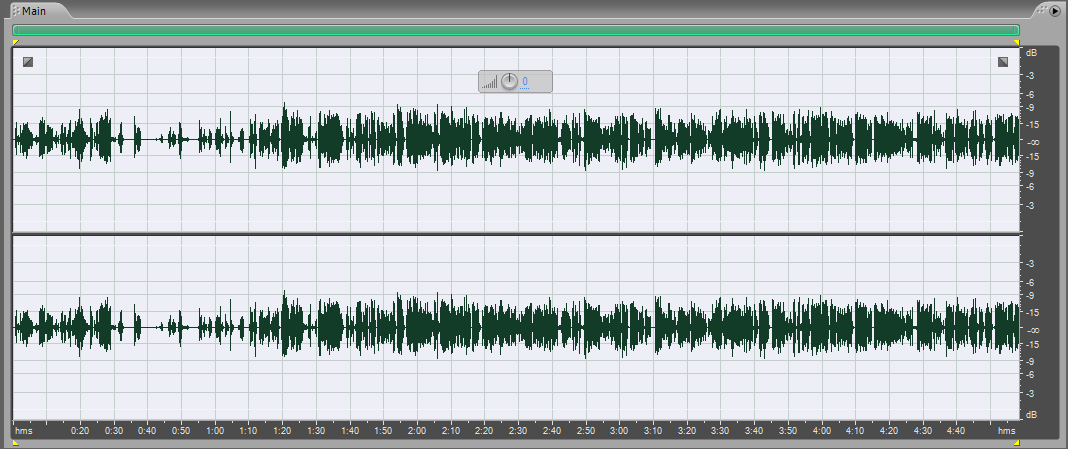
Очевидно, что сигнал упал по амплитуде, но в среднем он “отжался”, то есть выровнялся. Затем опять его нормализуем и получаем такую, достаточно ровненькую, реализацию.
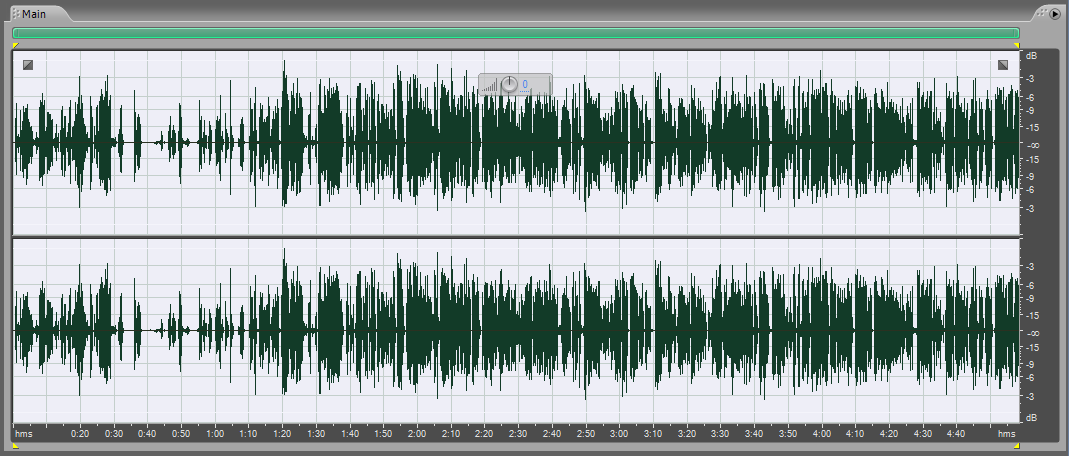
Можно, конечно, ещё компрессировать, но в этом случае могут начаться искажения голоса. Возможно YouTube это по барабану, но слушать это будет уже не совсем комильфо. Хотя… Смотрите сами.
При желании те фрагменты реализации, на которых сигнал достаточно мал даже после компрессии, как здесь,
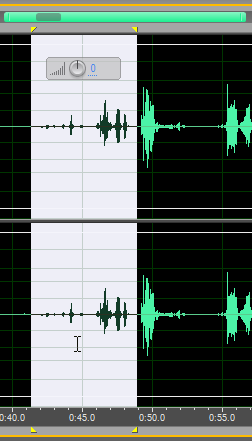
можно дополнительно усилить по амплитуде.
Пункт меню «Эффекты» → «Амплитуда и Компрессия» → «Усиление». Коэффициент усиления выберем равным +6 дБ.
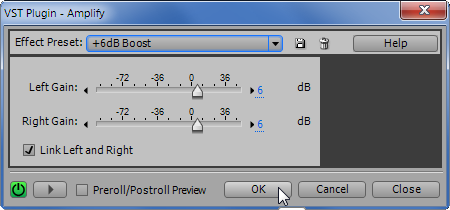
Жмём OK. Видим, как амплитуда выросла.
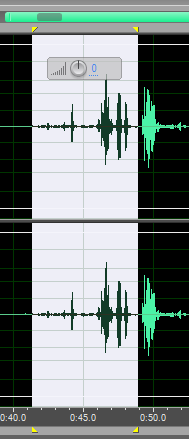
В принципе, вот так можно «побегать» по реализации и поподнимать уровень в «проблемных» местах. Что должно в общем дать эффект. Но это хорошо, когда таких участков немного. Если их там много, то можно замучиться. Хотя, если вы хотите получить хорошие результаты расшифровки текста, то придётся помучиться. Потому что это – палка о двух концах. Вы можете сэкономить время на обработке звука, но затем вам может понадобиться больше времени в процессе приведения в божеский вид того, что вам YouTube нарасшифрует.
Итак, на этом можно заканчивать обработку аудио записи. Самое главное – не забываем сохранять этот полученный нами результат.
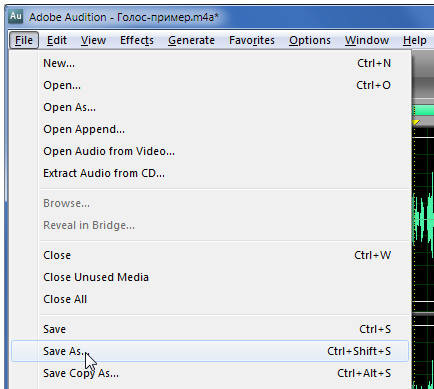
Например, в формате mp3.
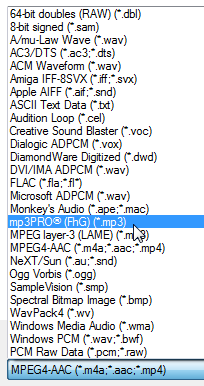
Жмём кнопку “Сохранить”.
Реагируем на предупреждение о том, что результат сохраняется в файл с потерями. Да, ладно!
Получив вот такой звуковой ряд из аудио записи своей защиты диссертации, вы сможете сформировать видеофайл, как я вас уже учил и рассказывал. После чего закинуть видео на YouTube, и пусть уж YouTube вместо вас «карячится» и превращает его в текст.
А о том, как из текстовой «каши», сваренной YouTube, сделать более приятное читабельное «блюдо»– чуть попозже.
На этом – всё. Закрываемся и выходим из программы.
До свидания! Успехов в работе над диссертацией!